This post originally appeared on the Ad Hoc blog, coauthored with my delightful colleague Ari Hershowitz. I'm reproducing it here, lightly edited for formatting and clarity.
Over the last 15 years, government has made meaningful progress modernizing its services. Agencies and their digital service teams have moved critical processes online. Cloud computing, accessibility, and user-centered design are now baseline expectations.
At the same time, many foundational policy documents were created for a hard-copy world. They remain comprehensive and authoritative, but they were not originally designed for structured, interactive digital use.
As part of February’s Free and Open Source Software Month, we’re open-sourcing an example of how agencies can responsibly use large language models (LLMs) to transform long-form policy documents into a structured, user-friendly digital experience. In this blog post, we’ll share more details on our approach.
The Copyright Compendium
The U.S. Copyright Office, within the Library of Congress, administers and interprets the nation’s copyright laws to promote creativity and free expression. Its impact is significant. In FY 2024, the Office facilitated access to more than 1.3 million works for the Library of Congress, representing an estimated $176 million in cultural value, and nearly half a million applicants, from movie studios to individual creators, sought copyright protection. The broader copyright-intensive industries supported by this system account for roughly $1.5 trillion annually, about 7 percent of U.S. GDP.
All this critical work needs a definitive set of instructions, and that’s exactly where The Copyright Compendium comes in. The Compendium is where the Office publishes authoritative guidance on how to apply for and maintain copyrights, what is eligible for copyright, how to deal with copyrighted works, and other topics – and updates that guidance based on changes in the law and emerging technologies.
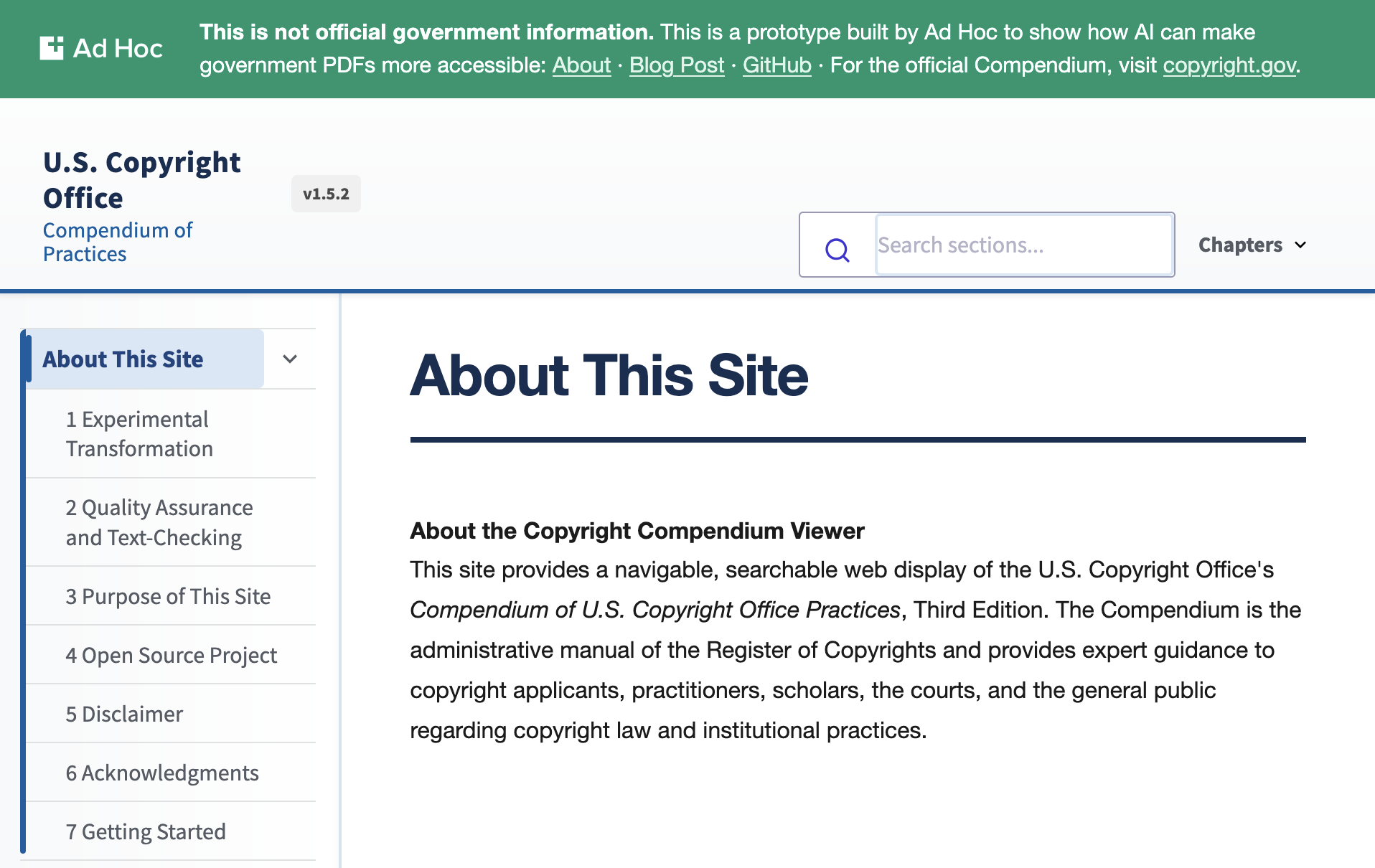
Today, the compendium is a 1,396-page reference guide that is available online as a single PDF document or divided into 24 individual chapters.
While comprehensive, navigating and locating specific information within a document of this size can be challenging. This reflects a common government pattern: critical information preserved in static artifacts that are not designed for digital interaction. It’s also a challenge that LLMs are great at solving: transforming information into structured formats.
Our approach
Over the course of two weeks, we combined LLM pdf-to-text transformation with an AI-enabled reading platform to make the Copyright Compendium easier to navigate, read, and understand.
We ensured the accuracy of this application through extensive testing: text comparison between the pdf and web pages, end-to-end automated testing and manual testing of the application itself, and a review of hundreds of glossary and legal citations.
First, we used Gemini to convert the PDF into structured XHTML. The transformation preserved hierarchy, semantics, and relationships across 24 chapters. We thoroughly tested the output to ensure that every word of the original text, and no extras, appeared in the structured content.
We then used AI-enabled development tools like Google Antigravity and Ad Hoc’s accelerators for accessible, quality digital experiences to rapidly create a digital-first experience that:
- Structures navigation by chapter and section
- Provides inline glossary definitions
- Hyperlinks citations where possible
- Provides browser-based translation using modern web APIs
- Makes the compendium easier to search by people, especially those with assistive technology, as well as search engines and LLMs
Ad Hoc subject matter experts with legal and regulatory expertise were able to harness AI to transform the almost 1400 pages of regulatory information and build a tested digital experience. In the past, similar efforts would have required months of custom parsing and manual development. This approach enabled one person to modernize a digital experience with speed and quality.
A responsible path forward
We see this as a reusable pattern for modernization. Across government, thousands of critical documents remain in PDF form. To keep systems aligned with evolving policy and public needs, agencies need practical ways to connect regulation, specification, and code with care and discipline. With secure platforms and AI-enabled transformation workflows, static artifacts can become structured, accessible systems while preserving accuracy and accountability at lower cost.
The Copyright Compendium project is a small but concrete example of what is possible today when you effectively use LLMs and AI-supported software development to amplify disciplined practice.
Secure developer platforms provide the foundation. Reusable accelerators encode best practices and compliance. AI handles transformation, synthesis, and repetitive implementation work. People retain accountability.
As part of February’s Free and Open Source Software Month, we invite you to explore the open source repository, search the updated experience, and consider how similar patterns could apply within your own agency.